Home › Forums › HAast (High Availability for Asterisk) › General › Call continuity / survival on failover › Reply To: Call continuity / survival on failover
Telium’s call continuity feature (available in HAAst OEM edition) maintains all SIP/RTP traffic data in the event of a failover. When HAAst transitions from one cluster node to another, HAAst reconstructs the calls in/out of Asterisk exposing identical IP/port numbers to the outside world. The allows calls to resume without any user agents realizing a cluster failover has taken place. HAAst can also initiate events with Asterisk to resume call recordings, log data, etc. ensuring business requirements can be satisfied as well.
If you cannot use Telium’s call continuity capability you can still create a simplistic workaround. First of all it’s important to understand the limitations of the SIP protocol (regardless of HA product), and then design around those limitations. The SIP protocol does not allow for the midpoints (e.g. PBX) or endpoints (e.g. phone) to be seized without the midpoints/endpoints participating in SIP negotiation. This means that failure of a midpoint or endpoint results in failure of the call(s) since SIP communications cease. A future version of SIP may support seizing channels, but the IETF has not indicated any such upcoming functionality.
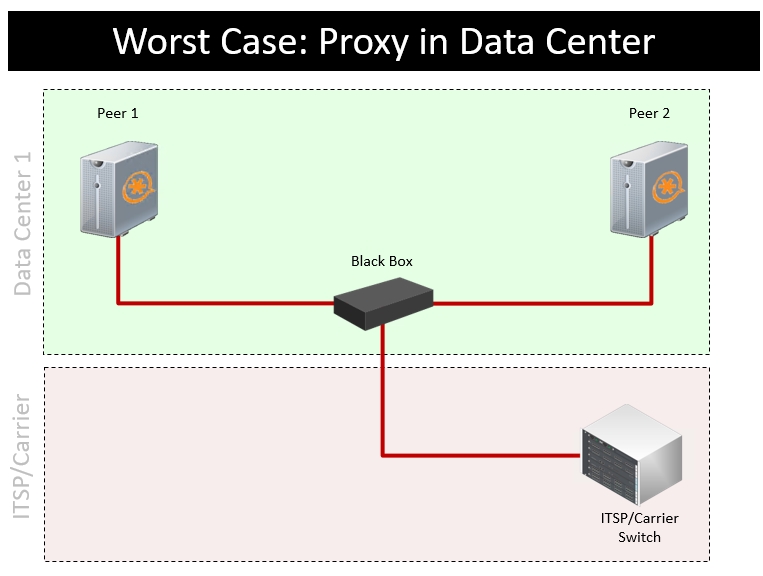
We know of at least one product on the market that claims a proprietary / ‘patented’ way to keep SIP calls up, but all they do is introduce a SIP proxy in front of the PBX which tries to re-establish the missing leg of a dropped call. These products don’t have much commercial success because they introduce a new single point of failure in front of the cluster (so if the proxy dies the entire cluster dies). In the case of power outage or network outage these proxy solutions do nothing and all calls drop. Telium has worked with vendors to design solutions for emergency call centers, hospitals, large commercial call centers, etc. and they all frown on placing a single point of failure in front of the cluster. An on-PBX solution (as offered by Telium) is the preferred solution.
Even large proprietary PBX vendors don’t support salvaging SIP calls in case of a complete PBX failure. They may offer “HA” options which transition calls in progress within or between PBX’s so long as the core of the PBX is still functional (so for example the PBX could withstand a media processor failure). However, they cannot salvage SIP calls in the event of a complete and immediate disconnect of the PBX (e.g. power failure, data center network failure, etc).
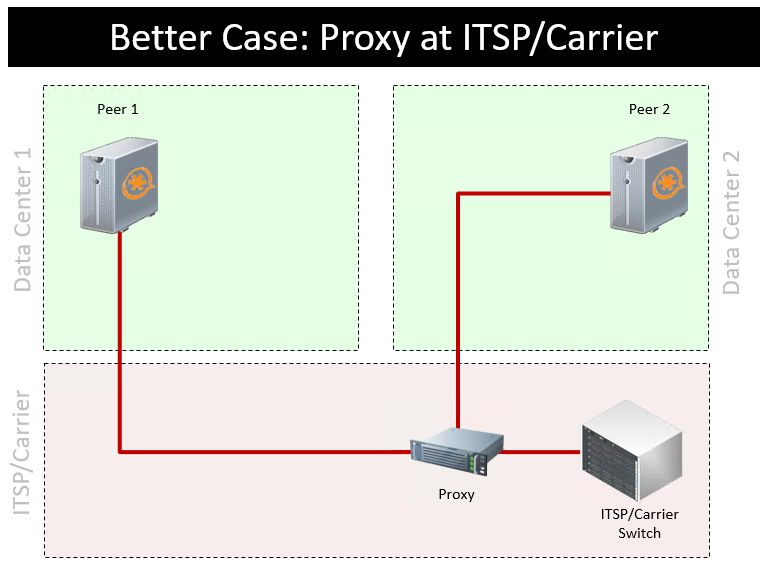
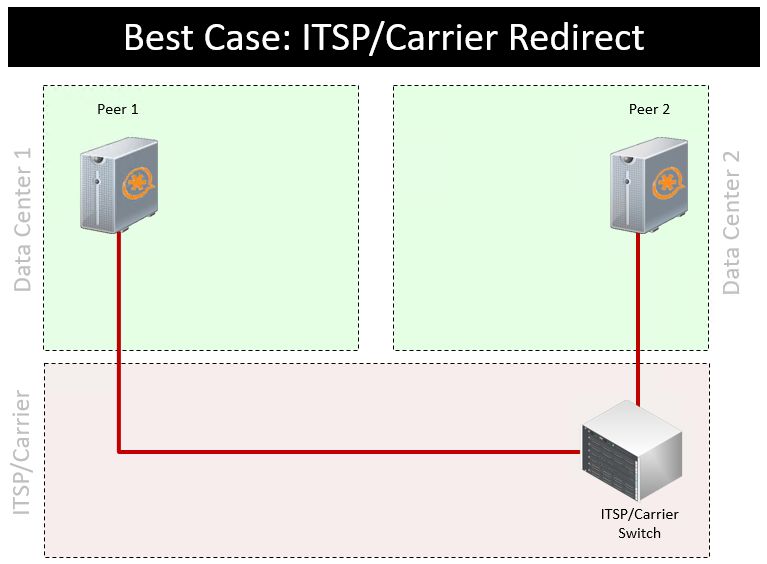
If you really want to try to salvage calls in progress (sometimes called ‘call continuity’ or ‘call survival’) with a do-it-yourself solution the best way to do so is at the ITSP/trunk provider. You can request that your carrier redirect any calls in progress which terminate without a SIP BYE command be redirected to a backup number/trunk. If your ITSP/Carrier will not do so, you can create your own SIP proxy but it should be collocated at your ITSP/carrier’s POP. Placing such a proxy on your premises is worthless (your cluster will appear to perform well in simplistic tests, but fail in real world outage scenarios), and is no different than the solutions mentioned above. You can try to use direct media with user agents (phones) that don’t drop a call if the SIP connection is unresponsive (eg; to registration) but this depends heavily on details of your implementation.
We would like to emphasize that Telium discourages adding a black box device or proxy in front of a cluster. However, if you still want to go down the DIY path you can create an open source version of the above (not recommended) product as described here: https://telium.io/topic/patented-call-survival-add-on/ or you could design a solution which attempts to keep RTP up without SIP (we have a few posts on that topic).