Forum Replies Created
-
AuthorPosts
-
in reply to: Do you support Debian Linux? #6710
And as of August 1 2017 we officially support Debian 9.
Please note that we only build 64 bit packages for newer distributions like Debian 9 / Ubuntu 16. If you require a 32 bit version for a recent OS please contact Telium support.
in reply to: Uninstall HAAst button #6712Linux does not have a ‘REMOVE PROGRAMS’ commandlet like Windows does – but some Linux distributions do offer a GUI to their package manager.
To uninstall HAAst you can simply reverse the steps in the installation guide, but in summary you need to:
- Delete the /usr/local/haast subdirectory
- Delete the /etc/xdg/telium subdirectory (assuming you have no other Telium products installed)
- Disable the HAAst service and remove the HAAst service file
- Remove the HAAst web config file and restart the HTTP server
And that’s it. There is no need to remove any prerequisite packages since they are at the OS level, and do nothing if not called upon by an application. (i.e. they don’t require CPU time, etc)
in reply to: Allow users to failover the PBX cluster #6711Yes. You can grant users limited monitoring and control capabilities through
- a LCD interface on the PBX (built in). HAAst supports LCD interfaces (see installation guide for models), and you can enabled control such that an end user can promote/demote a peer from the keypad on the front of the PBX. They can also confirm status, monitor synchronizations are happening, etc. from the LCD display.
- a simple web UI (which controls HAAst through the REST interface)
in reply to: License file sometimes rejected #6715In this case a defective video card caused the BIOS to sometimes detect a second network card, sometimes no second network card. The customer replaced the network card and the BIOS consistently detected the hardware. The license was then automatically accepted again.
Note that customers can add memory, change video cards, etc. without concern – we can just update the license for you. Send us a new license request and we’ll send you an updated license file. However, if your hardware appears to change on every boot then you need to fix that first.
Note that replacement licenses are free, but must be generated for a system under a maintenance agreement.
in reply to: License file sometimes rejected #6714The only time we have seen this problem is when some hardware is not being consistently detected by the BIOS (intermittent hardware), or the hardware changes the profile presented to Linux (e.g.: changing MAC address, changing CPU type, etc).
We can help you find the hardware causing this problem. Please submit two license request files: One from when the license is accepted, and one from when the license is rejected. We will run a comparison through our licensing tool and it will tell us what is different.
in reply to: Phones on some subnets can’t connect to PBX #6713There are several possible causes, all network configuration related. However, the most common cause has to do with the default route on your PBX causing an asymmetric network path.
In other words, packets come in ethernet1 and (try to) go out ethernet2. For security reasons some Linux versions prohibit this, and some routers/gateways can’t handle this. The first thing to do is ensure that your Linux configuration allows this type of asymmetrical path. Type the following from a Bash prompt:
echo “0” > /proc/sys/net/ipv4/conf/eth0/rp_filter
echo “0” > /proc/sys/net/ipv4/conf/eth1/rp_filterand replace eth0 and eth1 with the names of your network interfaces. This should take effect immediately (no restart required).
For more details of what the above commands do (and what problem they address) please visit https://access.redhat.com/solutions/53031 . Note that allowing asymmetric routes is sometimes the best solution, but other times it’s best to adjust your routing tables to cause symmetry in packet flow.
in reply to: Failed upgrade to FreePBX #6726If FreePBX is not too badly damaged (i.e. it has not messed up its own settings) you may be able to recover by just copying the full database with schema from the working node to the defective node. This assume you have followed all of the other advice in the installation guide regarding FreePBX modules/versions/etc.
If not, the Telium support team has tools to attempt to realign the two FreePBX installations. These tools move files/directories/databases/links etc to attempt to make FreePBX identical on both peers. Because of the potential to really make of mess of the peers, Telium does not offer these tools to the public. Instead you would need to purchase 2 hours of service (from the Buy tab) and grant direct SSH access to each peer. That’s usually the quickest route to recovery, but doesn’t always guarantee success (depending how badly the second peer is damaged).
If you want to recover the systems on your own, the next quickest way to recover your cluster is to mirror the primary PBX disk to the secondary PBX disk, and then adjust settings on the secondary to turn it into a unique peer. (Network settings, host name, and HAAst settings). Using ‘dd’ (or Ghost4Linux) is the easiest way to mirror the disk. Keep the secondary PBX unplugged from the network throughout this recovery, and resume at step 2 of the link you posted above.
After that your cluster will be up and running again!
In the future, I suggest you follow the HAAst Maintenance Guide before you apply any updates, or enable any FreePBX modules. Fortunately this problem is appears to be unique to FreePBX, as all other Asterisk based PBX’s we have encountered which use MySQL databases seem to detect any code-database mismatches and allow the user to simply UPDATE the configuration generator to recover.
Treat the FreePBX program as very fragile – so follow the upgrade instructions. As well, be sure to disable Automatic Updates in FreePBX as this too can cause problems.
in reply to: Failed upgrade to FreePBX #6724Regardless of how you update FreePBX(TM) (command line or GUI), you must follow the procedure listed in the HAAst maintenance guide – or the shortcut above.
By ignoring the instructions you have synced new database contents to old FreePBX code. FreePBX on the standby will be confused and refuse to start. The only solution is to bring the FreePBX code and database back into alignment.
I really hope you heeded our warning to BACKUP YOUR SYSTEM before applying any FreePBX’s updates, enabling modules, etc. The quickest solution is to unplug the standby and restore from the backup. After that resume at step 2 in the link you posted, and apply the same updates/changes you made to your active peer.
We see this problem a couple of times per year when a user doesn’t follow the upgrade instructions. The solution is simple: just restore your system level backup and resume at step 2 in the link you posted above.
Some users have described the FreePBX PHP code as ‘a tangled and fragile mess’. And we have seen FreePBX systems implode because of a (FreePBX) module changing the schema and other modules (or core FreePBX) didn’t like it. You must be very careful with FreePBX changes/updates. (This does not apply to other configuration generators or Asterisk itself).
in reply to: Call handling limit on Free Edition #6709The call handling limit of the Free Edition means that exceeding 3 simultaneous calls will shut down HAAst (and implicitly Asterisk with it).
The Free Edition allows you to test compatibility, features, usability, etc. which is usually sufficient for a trial, or even for a small office wishing to create a cluster. The Free Edition is not designed to handle the full call load of a mid to large size business, nor offer all features (of the Commercial Unlimited Edition).
If you wish to conduct a pilot with all features enabled and capacity limits removed we would be happy to work with you on the pilot (see https://telium.io/faq1002) and provide a temporary Commercial Unlimited Edition license.
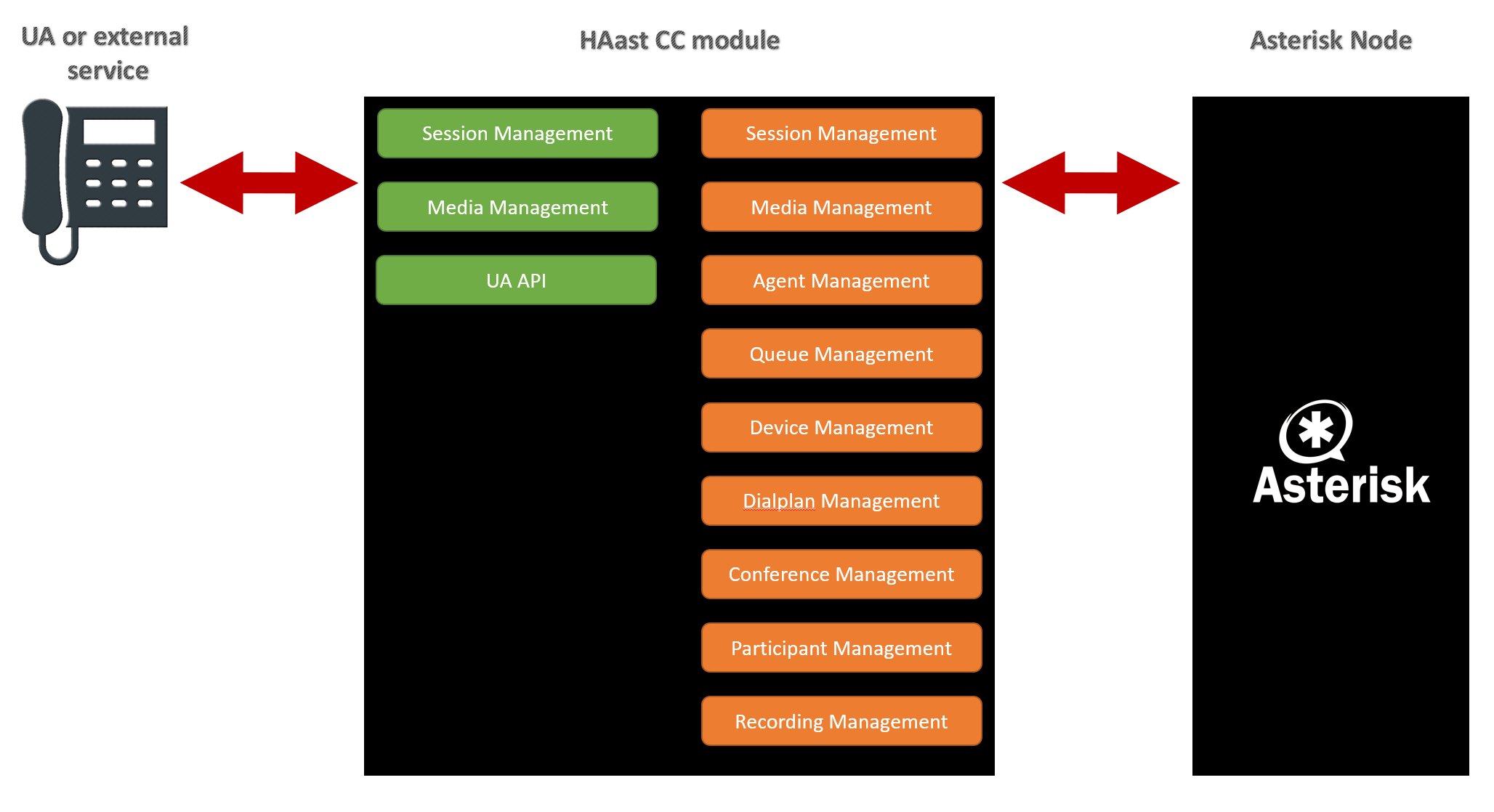
in reply to: HAast OEM Edition UA / unique ID is wrong #6708To understand what is going wrong you need to understand a bit more about the HAast CC module. The CC module acts like an SBC or proxy, in that all external UA’s (or services/devices) connect to the CC module, and the CC module connects to Asterisk. Each “session” is actually split into two sessions.
In the event of cluster failover the UA sessions move to the other node, while the Asterisk sessions are rebuilt. The CC module rebuilds conferences, queues, calls in progress, etc. on Asterisk and then bridges it back to the matching outside UA session.
With the Unlimited edition the call UniqueID found in asterisk matches what was seen at your gateway. With the OEM edition the call UniqueID found in Asterisk will be different that was is seen at your gateway (the CC module is bridging two separate sessions). In order to for your app to get the UniqueID (or any Asterisk variable) you must use the CC module API and ask it to provide a mapping between the external and internal session variables.
As customers become more sophisticated they often outgrow configuration generators and move to pure Asterisk(TM) from Digium. This has no impact on HAAst.
HAAst operates at a layer beneath Asterisk, so it doesn’t care if you change configuration generators, Asterisk versions, etc. Your license will continue to operate just fine after your switch.
in reply to: Cluster status via socket #6704To help customers trying to extract status information, here is a sample python script that retrieves and prints the local status:
# Example python script to retrieve local HAAst status
import socket
import sys
# End of packet marker
READYPROMPT=’ready>’
# Create a UDS socket
sock = socket.socket(socket.AF_UNIX, socket.SOCK_STREAM)
# Connect the socket to the port where the server is listening
server_address = ‘/run/haast.sock’
try:
sock.connect(server_address)
except socket.error, msg:
print >>sys.stderr, msg
sys.exit(1)
# Wait for a packet
def receivepacket():
global sock
total_data=[];data=”
while True:
data=sock.recv(8192)
if READYPROMPT in data:
total_data.append(data[:data.find(READYPROMPT)])
break
total_data.append(data)
if len(total_data)>2:
#check if end_of_data was split
last_pair=total_data[-2]+total_data[-1]
if READYPROMPT in last_pair:
total_data[-2]=last_pair[:last_pair.find(READYPROMPT)]
total_data.pop()
break
return ”.join(total_data).replace(‘r’,”).replace(‘nn’,’n’)
# Send a packet
def sendpacket(message):
global sock
success = 1
try:
# Send data
message += ‘nn’
# print >>sys.stderr, ‘sending “%s”‘%message
sock.sendall(message)
amount_received = 0
amount_expected = len(message)
while amount_received < amount_expected: data = sock.recv(16) amount_received += len(data) finally: # print >>sys.stderr, ‘closing socket’
# sock.close()
success = 0
return success
got = receivepacket()
sendpacket(“id:123ncommand:getstatus”)
got = receivepacket()
for item in got.split(“n”):
if “local haast state formatted:” in item:
print item.strip()
sock.close()
in reply to: Confusing instructions #6717We realize that some of our users are new to Linux, and that Asterisk may be the only reason they are working with Linux at all. Many long-time Windows admins have never used (or wanted to use) a command line and find the provided instructions frustrating and/or confusing.
The problem is that we offer a very technical product (with deep integration into Asterisk and the operating system, etc), requiring a level of Linux expertise that some admins don’t have. If we offered detailed explanations for each Linux command, networking concept, operating system parameter, etc. our installation guide would be huge. Sadly this is not an option for us.
If you are a commercial user we recommend purchasing installation assistance allowing our professional services group to perform the installation for/with you. We can offer a turnkey solution (from design through implementation) or just step in where you need help.
If you are a home user you may be better off using a ‘built-in’ option provided by one of the many configuration generators out there. You will be losing a substantial number of features and capabilities, but at least you can install a ‘built-in’ option by clicking BUY/INSTALL on a GUI. Please note that HAAst, SecAst, and SecData are targeted at large and critical commercial call centers – not home office / small office environments (Telium products are on a different scale than ‘built-in’ products/modules). You are welcome to use Telium products in home office / small office environments but realize that it’s like using an 18-wheel truck instead of a bicycle. As a home user the bicycle may be a better fit.
-
This reply was modified 6 years, 5 months ago by
WebMaster.
in reply to: Can’t download files – all transfer types fail #6716The most likely causes of your failures are as follows:
- FTP Pull: Your firewall is blocking incoming FTP data connections (TCP port 22). You can either enable incoming data connections on your firewall (not ideal), or preferably, set your FTP client to use ‘passive mode’.
- FTP Push: Your firewall is blocking incoming FTP control/data connection (TCP ports 21 and 22), or your FTP server is not running.
- wget: You forgot to add the ‘–content-disposition’ parameter to wget when using the HTTP URL. Either rename the downloaded file to match the package name, or add the –content-disposition parameter when using wget.
- browser: It sounds like your browser connection is being interrupted/corrupted, and the file you downloaded is corrupt. Verify the md5 checksum of the file and try again, or switch to one of the above (more reliable) transfer methods. Browser (HTTP) download is known to be unreliable.
in reply to: iptables+fireHOL not blocking IP’s #6705Glad you are up and running. If you need SecAst to recreate its iptables rules just restart the SecAst service (it will restore all banned IP since it keeps those in a recovery file). We’ll have to think about how/if SecAst should monitor the iptables. It’s unusual for the iptables rules to be lost (so SecAst shouldn’t have to check that) – but it’s on our discussion list.
In regards to downloading, what error exactly are you experiencing? (Corrupt download, or download won’t start, etc). Downloading by browser is often unreliable for large files, but FTP normally works perfectly. We just tried FTP (pull) and the file downloaded perfectly (no corruption, etc). We also tried downloading with Firefox version 53 (32 bit) and browser download worked fine 2 of 3 times (one time download was corrupt so it would not untar). Similarly downloading by Chrome worked 3 of 4 times. You can see why we offer FTP…browsers aren’t great for this kind of thing. (Since this is a different topic feel free to email support@telium.io if you have more details on file transfer issue)
-
AuthorPosts