Home › Forums › HAast (High Availability for Asterisk) › Configuration & Optimization › Node fail over if unrelated devices go down
-
AuthorPosts
-
I need my HAAst node to fail over if a device in my local data center goes down. The device is manageable over the network at address 1.2.3.4 [address changed by Telium support] in case that matters. How can I do this?
It sounds like you want the local HAAst node to monitor the health of an external device. The way to accomplish this is with a HAAst health sensor.
At the simplest level I would suggest you create a sensor to monitor whether or not the device is responding to pings. For example, pasted the following code to /etc/xdg/telium/haast.conf.d/mydevice.sensors.conf
; Test if mydevice is reachable and responsive
network-connection/description=Ensure mydevice is reachable and responsive
network-connection/type=ping
network-connection/input=received
network-connection/parameters=count:3 | interface:ens1 | host:1.2.3.4
network-connection/scoring= =3:0 | =2:30 | =1:50 | :70
network-connection/warningscore=30
network-connection/errorscore=70
network-connection/resetcumulativescore=0
network-connection/interval=10
Restart HAAst and the sensor will become live. You should now see the local peer health score change based on the result of the above sensor.
I’ll explain the example more:
- The sensors pings the device 3 times through interface ens1.
- If 3 responses are received, then the health score for this sensor is 0; if 2 are received the health score is 30; if 1 is received the health score is 50; if none are received the health score is 70.
- If there is a warning from the ping (eg: no route) then a score of 30 is used. If there is a error (eg: ping cant run) then a score of 70 is used.
- The sensor runs every 10 seconds. (Since the ping command runs for 3-4 seconds that would be a 40% duty cycle).
- If the score ever returns 0, then the cumulative score for this sensor is reset to 0. Remember that each sensor’s score is cumulative, so it grows over time if the sensor keeps failing.
To make the above work, you also have to adjust your sensors settings in haast.conf If this is the only sensor in use then it is quite simple, but you may wish to create many such sensors to monitor other critical devices. In this case you could set your haast.conf settings as follows:
- criticallevel=70
- criticalresetlevel=40
- failurelevel=100
Note that the level settings in haast.conf check totals cores (across all sensors), and that individual sensor scores are cumulative. So in the example above missing 1 ping out of 3 each time the sensor runs will cause the sensor’s cumulative score to go 0 -> 30 -> 60 -> 90 -> 120. When it reaches 70 a critical alert can be sent (an event handler can run), and when it reaches 100 the local peer will declare failure and initiate a fail over.
As scoring tends to be more difficult to understand, here another example. The following graph shows the health score of the sensor over time (seconds). You can see from the blue boxes when a sensor starts (every 10 seconds), and when it ends (approx 4 seconds later). Based on the result of the ping responses (pongs), the number of packets received will cause a score to be calculated. The cumulative health score (in yellow) grows over time as the sensors detects missed pongs.
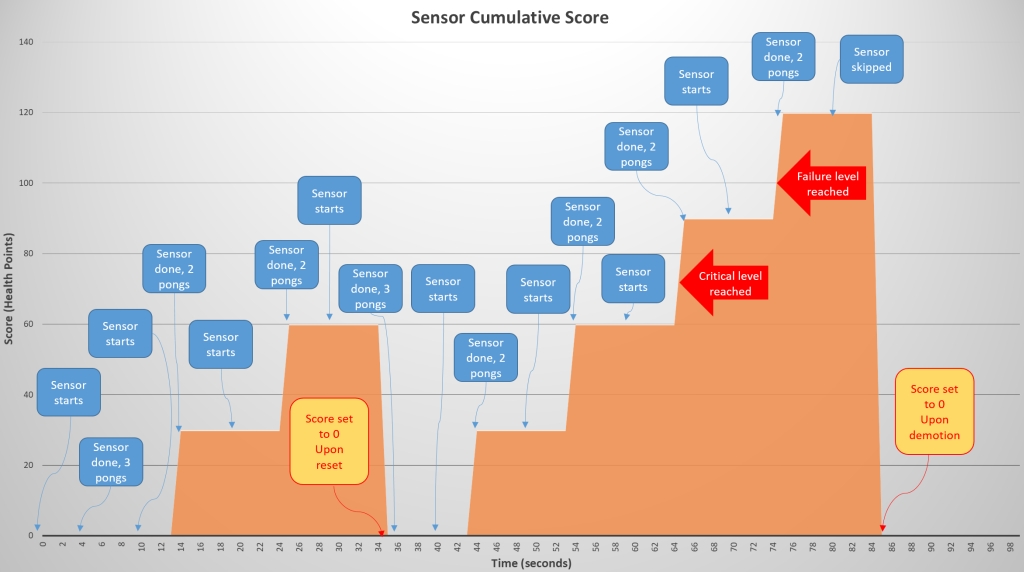
You can see at time 34s that all pongs where received and the cumulative score returns to 0. At time 64s the cumulative score has reached the critical level (70) and the critical event handler is trigger. At time 74s the cumulative score has reached the failure level and the node triggers the fail over process to the peer. Once the other node is active the local health score returns to 0 around time 84s.
This example is a simple ping test, but if your device offers health information through a REST API, telnet interface, etc. then you could create an even more sophisticated sensor.
I would suggest you experiment with disabling the ens1 NIC on your host, and watch the health score increase and then failover in HAAst. (Through the HAAst GUI or through the HAAst telnet interface). Once it works perfectly you could create similar sensors for HAAst on the other peer.
-
AuthorPosts
- You must be logged in to reply to this topic.